7.0 KiB
This model was published in HF papers on 2025-08-08 and contributed to Hugging Face Transformers on 2025-07-21.
GLM-4.5, GLM-4.6, GLM-4.7
Overview
GLM-4.7, GLM-4.6 and GLM-4.5 language model use this class. The implementation in transformers does not include an MTP layer.
GLM-4.7
GLM-4.7, your new coding partner, is coming with the following features:
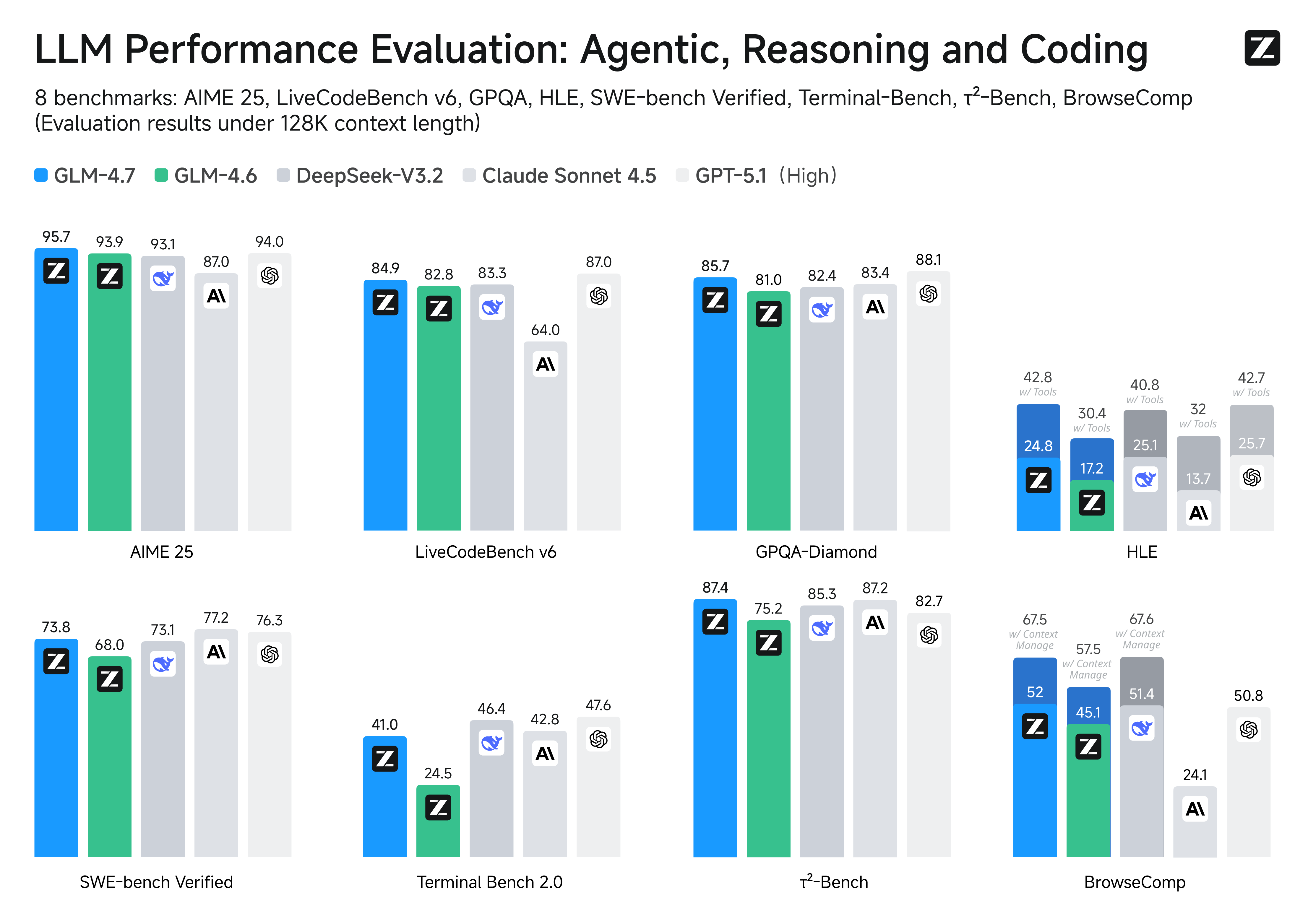
- Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
- Vibe Coding: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
- Tool Using: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
- Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
More general, one would also witness significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
Interleaved Thinking & Preserved Thinking
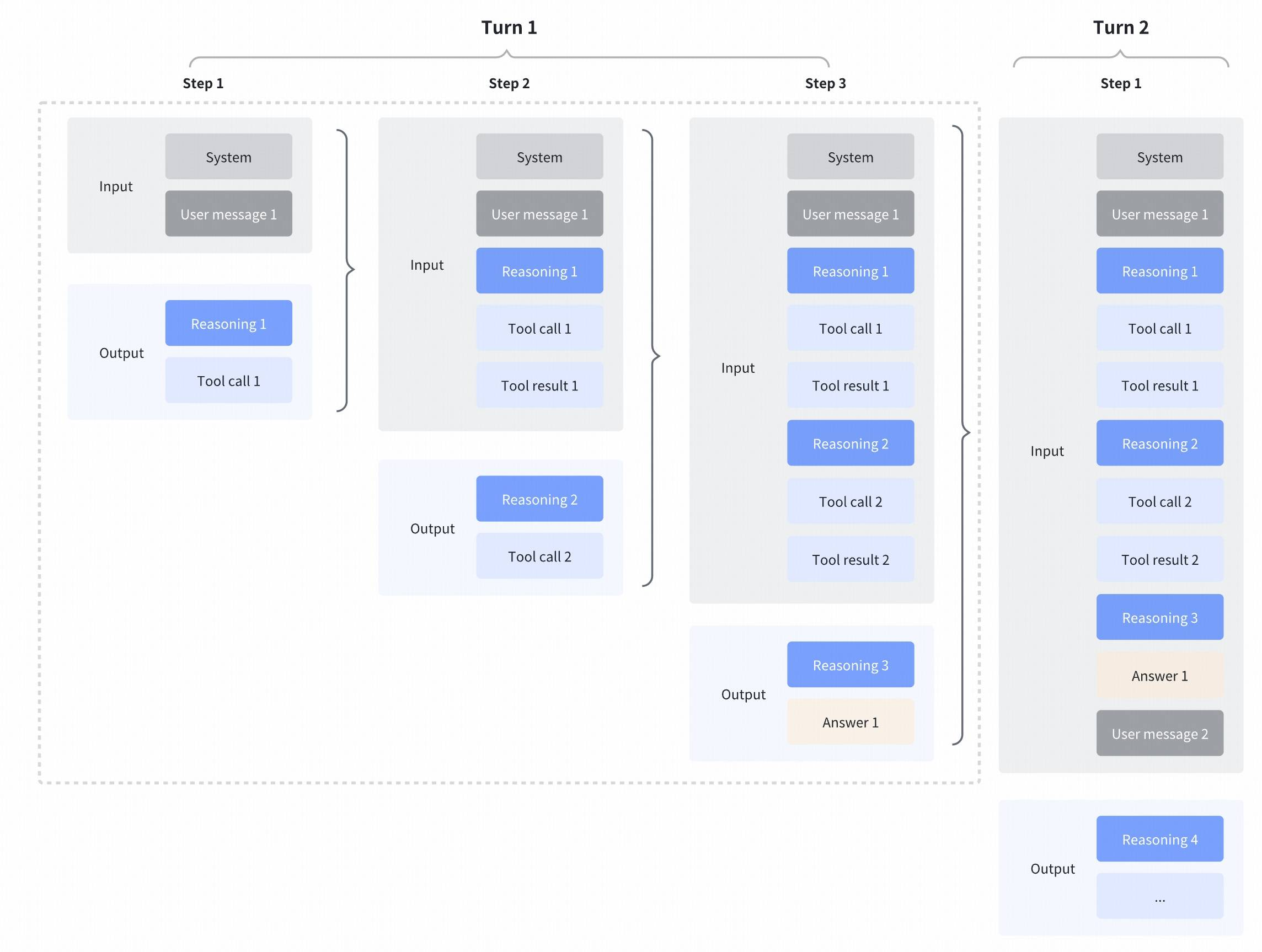
GLM-4.7 further enhances Interleaved Thinking (a feature introduced since GLM-4.5) and introduces Preserved Thinking and Turn-level Thinking. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable:
- Interleaved Thinking: The model thinks before every response and tool calling, improving instruction following and the quality of generation.
- Preserved Thinking: In coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations, reusing the existing reasoning instead of re-deriving from scratch. This reduces information loss and inconsistencies, and is well-suited for long-horizon, complex tasks.
- Turn-level Thinking: The model supports per-turn control over reasoning within a session—disable thinking for lightweight requests to reduce latency/cost, enable it for complex tasks to improve accuracy and stability.
More details: https://docs.z.ai/guides/capabilities/thinking-mode
For more eval results, show cases, and technical details, please visit GLM-4.7 technical blog.
GLM-4.6
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
- Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
- Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
- Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
- More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
- Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
For more eval results, show cases, and technical details, please visit GLM-4.6 technical blog.
GLM-4.5
The GLM-4.5 series models are foundation models designed for intelligent agents, MoE variants are documented here as Glm4Moe.
GLM-4.5 has 355 billion total parameters with 32 billion active parameters, while GLM-4.5-Air adopts a more compact design with 106 billion total parameters and 12 billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of 63.2, in the 3rd place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at 59.8 while maintaining superior efficiency.
For more eval results, show cases, and technical details, please visit our technical report or technical blog.
The model code, tool parser and reasoning parser can be found in the implementation of transformers, vLLM and SGLang.
Glm4MoeConfig
autodoc Glm4MoeConfig
Glm4MoeModel
autodoc Glm4MoeModel - forward
Glm4MoeForCausalLM
autodoc Glm4MoeForCausalLM - forward