12 KiB
This model was published in HF papers on 2024-01-08 and contributed to Hugging Face Transformers on 2023-12-11.
Mixtral
Overview
Mixtral-8x7B was introduced in the Mixtral of Experts blogpost by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
The introduction of the blog post says:
Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.
Mixtral-8x7B is the second large language model (LLM) released by mistral.ai, after Mistral-7B.
Architectural details
Mixtral-8x7B is a decoder-only Transformer with the following architectural choices:
- Mixtral is a Mixture of Experts (MoE) model with 8 experts per MLP, with a total of 45 billion parameters. To learn more about mixture-of-experts, refer to the blog post.
- Despite the model having 45 billion parameters, the compute required for a single forward pass is the same as that of a 14 billion parameter model. This is because even though each of the experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dispatched twice (top 2 routing) and thus the compute (the operation required at each forward computation) is just 2 X sequence_length.
The following implementation details are shared with Mistral AI's first model Mistral-7B:
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
For more details refer to the release blog post.
License
Mixtral-8x7B is released under the Apache 2.0 license.
Usage tips
The Mistral team has released 2 checkpoints:
- a base model, Mixtral-8x7B-v0.1, which has been pre-trained to predict the next token on internet-scale data.
- an instruction tuned model, Mixtral-8x7B-Instruct-v0.1, which is the base model optimized for chat purposes using supervised fine-tuning (SFT) and direct preference optimization (DPO).
The base model can be used as follows:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
prompt = "My favourite condiment is"
model_inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
tokenizer.batch_decode(generated_ids)[0]
"My favourite condiment is to ..."
The instruction tuned model can be used as follows:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
tokenizer.batch_decode(generated_ids)[0]
"Mayonnaise can be made as follows: (...)"
As can be seen, the instruction-tuned model requires a chat template to be applied to make sure the inputs are prepared in the right format.
Speeding up Mixtral by using Flash Attention
The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging Flash Attention, which is a faster implementation of the attention mechanism used inside the model.
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the flash attention repository. Make also sure to load your model in half-precision (e.g. torch.float16)
To load and run a model using Flash Attention-2, refer to the snippet below:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", attn_implementation="flash_attention_2", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
prompt = "My favourite condiment is"
model_inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
tokenizer.batch_decode(generated_ids)[0]
"The expected output"
Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using mistralai/Mixtral-8x7B-v0.1 checkpoint and the Flash Attention 2 version of the model.
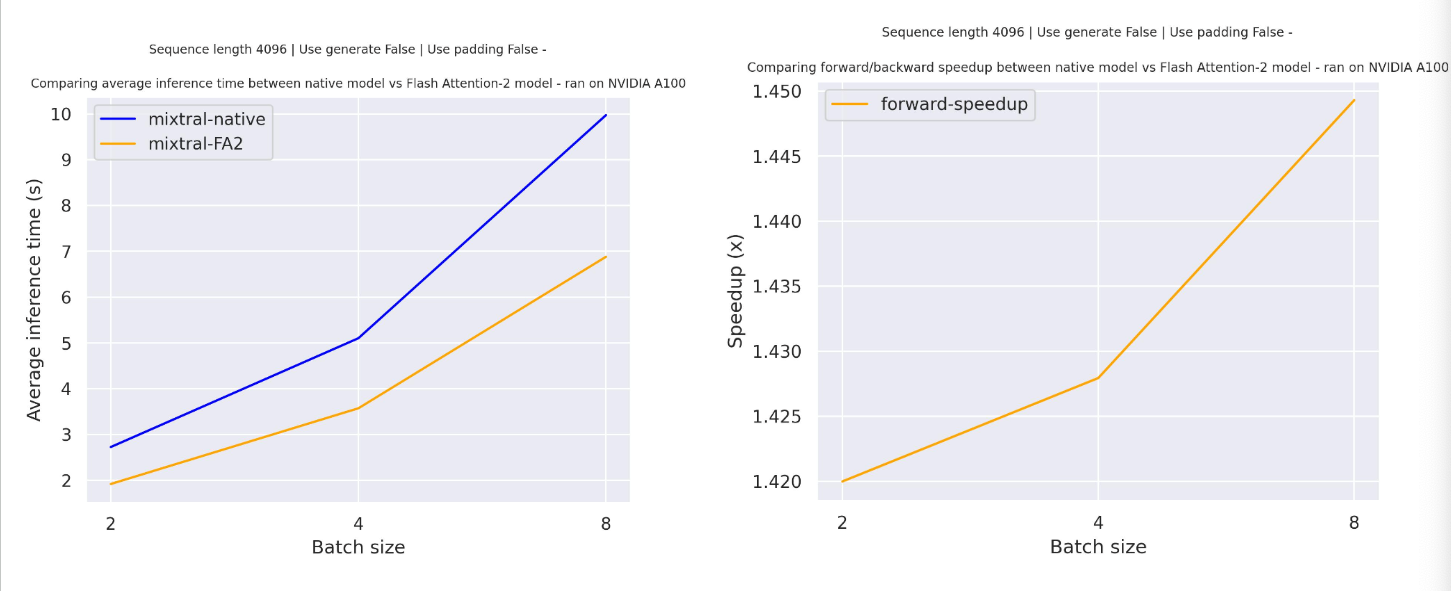
Sliding window Attention
The current implementation supports the sliding window attention mechanism and memory efficient cache management.
To enable sliding window attention, just make sure to have a flash-attn version that is compatible with sliding window attention (>=2.3.0).
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (self.config.sliding_window), support batched generation only for padding_side="left" and use the absolute position of the current token to compute the positional embedding.
Shrinking down Mixtral using quantization
As the Mixtral model has 45 billion parameters, that would require about 90GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using quantization. If the model is quantized to 4 bits (or half a byte per parameter), a single A100 with 40GB of RAM is enough to fit the entire model, as in that case only about 27 GB of RAM is required.
Quantizing a model is as simple as passing a quantization_config to the model. Below, we'll leverage the bitsandbytes quantization library (but refer to this page for alternative quantization methods):
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# specify how to quantize the model
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="torch.float16",
)
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", quantization_config=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = "My favourite condiment is"
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
tokenizer.batch_decode(generated_ids)[0]
"The expected output"
This model was contributed by Younes Belkada and Arthur Zucker . The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mixtral. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A demo notebook to perform supervised fine-tuning (SFT) of Mixtral-8x7B can be found here. 🌎
- A blog post on fine-tuning Mixtral-8x7B using PEFT. 🌎
- The Alignment Handbook by Hugging Face includes scripts and recipes to perform supervised fine-tuning (SFT) and direct preference optimization with Mistral-7B. This includes scripts for full fine-tuning, QLoRa on a single accelerator as well as multi-accelerator fine-tuning.
- Causal language modeling task guide
MixtralConfig
autodoc MixtralConfig
MistralCommonBackend
autodoc MistralCommonBackend
MixtralModel
autodoc MixtralModel - forward
MixtralForCausalLM
autodoc MixtralForCausalLM - forward
MixtralForSequenceClassification
autodoc MixtralForSequenceClassification - forward
MixtralForTokenClassification
autodoc MixtralForTokenClassification - forward
MixtralForQuestionAnswering
autodoc MixtralForQuestionAnswering - forward