4.4 KiB
This model was published in HF papers on 2021-06-01 and contributed to Hugging Face Transformers on 2022-05-02.
YOLOS
YOLOS uses a Vision Transformer (ViT) for object detection with minimal modifications and region priors. It can achieve performance comparable to specialized object detection models and frameworks with knowledge about 2D spatial structures.
You can find all the original YOLOS checkpoints under the HUST Vision Lab organization.
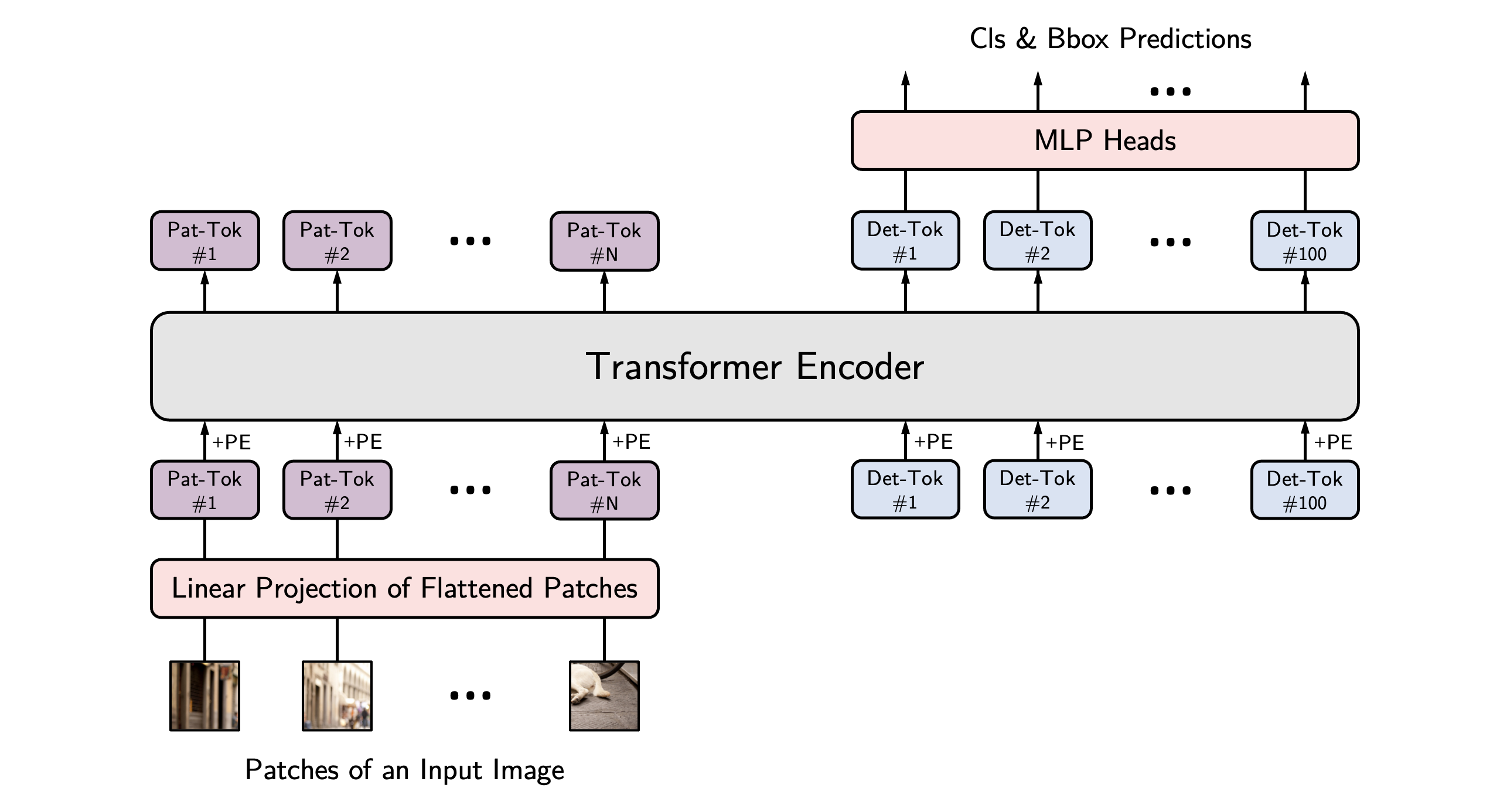
YOLOS architecture. Taken from the original paper.
Tip
This model wasa contributed by nielsr. Click on the YOLOS models in the right sidebar for more examples of how to apply YOLOS to different object detection tasks.
The example below demonstrates how to detect objects with [Pipeline] or the [AutoModel] class.
from transformers import pipeline
detector = pipeline(
task="object-detection",
model="hustvl/yolos-base",
device=0
)
detector("https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png")
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("hustvl/yolos-base")
model = AutoModelForObjectDetection.from_pretrained("hustvl/yolos-base", attn_implementation="sdpa", device_map="auto")
url = "https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
inputs = processor(images=image, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits.softmax(-1)
scores, labels = logits[..., :-1].max(-1)
boxes = outputs.pred_boxes
threshold = 0.3
keep = scores[0] > threshold
filtered_scores = scores[0][keep]
filtered_labels = labels[0][keep]
filtered_boxes = boxes[0][keep]
width, height = image.size
pixel_boxes = filtered_boxes * torch.tensor([width, height, width, height], device=boxes.device)
for score, label, box in zip(filtered_scores, filtered_labels, pixel_boxes):
x0, y0, x1, y1 = box.tolist()
print(f"Label {model.config.id2label[label.item()]}: {score:.2f} at [{x0:.0f}, {y0:.0f}, {x1:.0f}, {y1:.0f}]")
Notes
- Use [
YolosImageProcessor] for preparing images (and optional targets) for the model. Contrary to DETR, YOLOS doesn't require apixel_mask.
Resources
- Refer to these notebooks for inference and fine-tuning with [
YolosForObjectDetection] on a custom dataset.
YolosConfig
autodoc YolosConfig
YolosImageProcessor
autodoc YolosImageProcessor - preprocess
YolosImageProcessorPil
autodoc YolosImageProcessorPil - preprocess - pad - post_process_object_detection
YolosModel
autodoc YolosModel - forward
YolosForObjectDetection
autodoc YolosForObjectDetection - forward