5.4 KiB
Audio Spectrogram Transformer
概要
Audio Spectrogram Transformerモデルは、AST: Audio Spectrogram Transformerという論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声にVision Transformerを適用します。このモデルは音声分類において最先端の結果を得ています。
論文の要旨は以下の通りです:
過去10年間で、畳み込みニューラルネットワーク(CNN)は、音声スペクトログラムから対応するラベルへの直接的なマッピングを学習することを目指す、エンドツーエンドの音声分類モデルの主要な構成要素として広く採用されてきました。長距離のグローバルなコンテキストをより良く捉えるため、最近の傾向として、CNNの上にセルフアテンション機構を追加し、CNN-アテンションハイブリッドモデルを形成することがあります。しかし、CNNへの依存が必要かどうか、そして純粋にアテンションに基づくニューラルネットワークだけで音声分類において良いパフォーマンスを得ることができるかどうかは明らかではありません。本論文では、これらの問いに答えるため、音声分類用では最初の畳み込みなしで純粋にアテンションベースのモデルであるAudio Spectrogram Transformer(AST)を紹介します。我々はASTを様々なオーディオ分類ベンチマークで評価し、AudioSetで0.485 mAP、ESC-50で95.6%の正解率、Speech Commands V2で98.1%の正解率という新たな最先端の結果を達成しました。
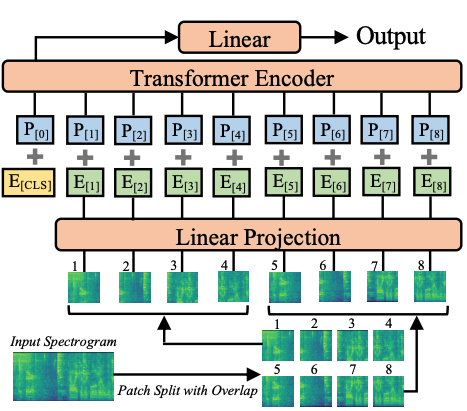
Audio Spectrogram Transformerのアーキテクチャ。元論文より抜粋。
このモデルはnielsrより提供されました。 オリジナルのコードはこちらで見ることができます。
使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[
ASTFeatureExtractor]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、ast/src/get_norm_stats.pyで確認することができます。 - ASTは低い学習率が必要であり 著者はPSLA論文で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
参考資料
Audio Spectrogram Transformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。
- ASTを用いた音声分類の推論を説明するノートブックはこちらで見ることができます。
- [
ASTForAudioClassification]は、この例示スクリプトとノートブックによってサポートされています。 - こちらも参照:音声分類タスク。
ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
ASTConfig
autodoc ASTConfig
ASTFeatureExtractor
autodoc ASTFeatureExtractor - call
ASTModel
autodoc ASTModel - forward
ASTForAudioClassification
autodoc ASTForAudioClassification - forward