Some checks failed
Self-hosted runner (nightly-past-ci-caller) / Get number (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.11 (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.10 (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.9 (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.8 (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.7 (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.6 (push) Has been cancelled
Self-hosted runner (nightly-past-ci-caller) / TensorFlow 2.5 (push) Has been cancelled
Self-hosted runner (benchmark) / Benchmark (aws-g5-4xlarge-cache) (push) Has been cancelled
Build documentation / build (push) Has been cancelled
Build documentation / build_other_lang (push) Has been cancelled
CodeQL Security Analysis / CodeQL Analysis (push) Has been cancelled
New model PR merged notification / Notify new model (push) Has been cancelled
PR CI / pr-ci (push) Has been cancelled
Slow tests on important models (on Push - A10) / Get all modified files (push) Has been cancelled
Secret Leaks / trufflehog (push) Has been cancelled
Update Transformers metadata / build_and_package (push) Has been cancelled
Slow tests on important models (on Push - A10) / Model CI (push) Has been cancelled
Check Tiny Models / Check tiny models (push) Has been cancelled
Self-hosted runner (Intel Gaudi3 scheduled CI caller) / Model CI (push) Has been cancelled
Self-hosted runner (Intel Gaudi3 scheduled CI caller) / Pipeline CI (push) Has been cancelled
Self-hosted runner (Intel Gaudi3 scheduled CI caller) / Example CI (push) Has been cancelled
Self-hosted runner (Intel Gaudi3 scheduled CI caller) / DeepSpeed CI (push) Has been cancelled
Self-hosted runner (Intel Gaudi3 scheduled CI caller) / Trainer/FSDP CI (push) Has been cancelled
Nvidia CI - Flash Attn / Setup (push) Has been cancelled
Nvidia CI - Flash Attn / Model CI (push) Has been cancelled
Nvidia CI / Setup (push) Has been cancelled
Nvidia CI / Model CI (push) Has been cancelled
Nvidia CI / Torch pipeline CI (push) Has been cancelled
Nvidia CI / Example CI (push) Has been cancelled
Nvidia CI / Trainer/FSDP CI (push) Has been cancelled
Nvidia CI / DeepSpeed CI (push) Has been cancelled
Nvidia CI / Quantization CI (push) Has been cancelled
Nvidia CI / Kernels CI (push) Has been cancelled
Doctests / Setup (push) Has been cancelled
Doctests / Call doctest jobs (push) Has been cancelled
Doctests / Send results to webhook (push) Has been cancelled
Extras Smoke Test / Get supported Python versions (push) Has been cancelled
Extras Smoke Test / Test extras on Python ${{ matrix.python-version }} (push) Has been cancelled
Extras Smoke Test / Check Slack token availability (push) Has been cancelled
Extras Smoke Test / Notify failures to Slack (push) Has been cancelled
Self-hosted runner (AMD scheduled CI caller) / Trigger Scheduled AMD CI (push) Has been cancelled
Stale Bot / Close Stale Issues (push) Has been cancelled
208 lines
10 KiB
Markdown
208 lines
10 KiB
Markdown
<!---
|
|
Copyright 2022 The HuggingFace Team. All rights reserved.
|
|
|
|
Licensed under the Apache License, Version 2.0 (the "License");
|
|
you may not use this file except in compliance with the License.
|
|
You may obtain a copy of the License at
|
|
|
|
http://www.apache.org/licenses/LICENSE-2.0
|
|
|
|
Unless required by applicable law or agreed to in writing, software
|
|
distributed under the License is distributed on an "AS IS" BASIS,
|
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
|
See the License for the specific language governing permissions and
|
|
limitations under the License.
|
|
-->
|
|
|
|
# Semantic segmentation examples
|
|
|
|
This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForSemanticSegmentation` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSemanticSegmentation) (such as [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer), [BEiT](https://huggingface.co/docs/transformers/main/en/model_doc/beit), [DPT](https://huggingface.co/docs/transformers/main/en/model_doc/dpt)) using PyTorch.
|
|
|
|
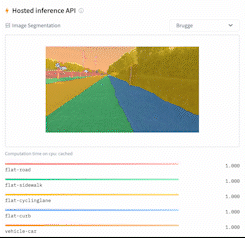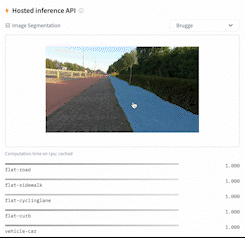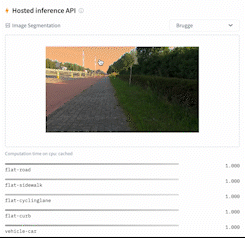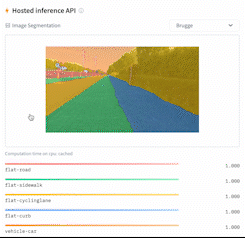
|
|
|
|
Content:
|
|
* [Note on custom data](#note-on-custom-data)
|
|
* [PyTorch version, Trainer](#pytorch-version-trainer)
|
|
* [PyTorch version, no Trainer](#pytorch-version-no-trainer)
|
|
* [Reload and perform inference](#reload-and-perform-inference)
|
|
* [Important notes](#important-notes)
|
|
|
|
## Note on custom data
|
|
|
|
In case you'd like to use the script with custom data, there are 2 things required: 1) creating a DatasetDict 2) creating an id2label mapping. Below, these are explained in more detail.
|
|
|
|
### Creating a `DatasetDict`
|
|
|
|
The script assumes that you have a `DatasetDict` with 2 columns, "image" and "label", both of type [Image](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Image). This can be created as follows:
|
|
|
|
```python
|
|
from datasets import Dataset, DatasetDict, Image
|
|
|
|
# your images can of course have a different extension
|
|
# semantic segmentation maps are typically stored in the png format
|
|
image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"]
|
|
label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
|
|
|
|
# same for validation
|
|
# image_paths_validation = [...]
|
|
# label_paths_validation = [...]
|
|
|
|
def create_dataset(image_paths, label_paths):
|
|
dataset = Dataset.from_dict({"image": sorted(image_paths),
|
|
"label": sorted(label_paths)})
|
|
dataset = dataset.cast_column("image", Image())
|
|
dataset = dataset.cast_column("label", Image())
|
|
|
|
return dataset
|
|
|
|
# step 1: create Dataset objects
|
|
train_dataset = create_dataset(image_paths_train, label_paths_train)
|
|
validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
|
|
|
|
# step 2: create DatasetDict
|
|
dataset = DatasetDict({
|
|
"train": train_dataset,
|
|
"validation": validation_dataset,
|
|
}
|
|
)
|
|
|
|
# step 3: push to hub (assumes you have ran the hf auth login command in a terminal/notebook)
|
|
dataset.push_to_hub("name of repo on the hub")
|
|
|
|
# optionally, you can push to a private repo on the hub
|
|
# dataset.push_to_hub("name of repo on the hub", private=True)
|
|
```
|
|
|
|
An example of such a dataset can be seen at [nielsr/ade20k-demo](https://huggingface.co/datasets/nielsr/ade20k-demo).
|
|
|
|
### Creating an id2label mapping
|
|
|
|
Besides that, the script also assumes the existence of an `id2label.json` file in the repo, containing a mapping from integers to actual class names. An example of that can be seen [here](https://huggingface.co/datasets/nielsr/ade20k-demo/blob/main/id2label.json). This can be created in Python as follows:
|
|
|
|
```python
|
|
import json
|
|
# simple example
|
|
id2label = {0: 'cat', 1: 'dog'}
|
|
with open('id2label.json', 'w') as fp:
|
|
json.dump(id2label, fp)
|
|
```
|
|
|
|
You can easily upload this by clicking on "Add file" in the "Files and versions" tab of your repo on the hub.
|
|
|
|
## PyTorch version, Trainer
|
|
|
|
Based on the script [`run_semantic_segmentation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
|
|
|
|
The script leverages the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
|
|
|
|
Here we show how to fine-tune a [SegFormer](https://huggingface.co/nvidia/mit-b0) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset:
|
|
|
|
In order to use `segments/sidewalk-semantic`:
|
|
- Log in to Hugging Face with `hf auth login` (token can be accessed [here](https://huggingface.co/settings/tokens)).
|
|
- Accept terms of use for `sidewalk-semantic` on [dataset page](https://huggingface.co/datasets/segments/sidewalk-semantic).
|
|
|
|
```bash
|
|
python run_semantic_segmentation.py \
|
|
--model_name_or_path nvidia/mit-b0 \
|
|
--dataset_name segments/sidewalk-semantic \
|
|
--output_dir ./segformer_outputs/ \
|
|
--remove_unused_columns False \
|
|
--do_train \
|
|
--do_eval \
|
|
--push_to_hub \
|
|
--push_to_hub_model_id segformer-finetuned-sidewalk-10k-steps \
|
|
--max_steps 10000 \
|
|
--learning_rate 0.00006 \
|
|
--lr_scheduler_type polynomial \
|
|
--per_device_train_batch_size 8 \
|
|
--per_device_eval_batch_size 8 \
|
|
--logging_strategy steps \
|
|
--logging_steps 100 \
|
|
--eval_strategy epoch \
|
|
--save_strategy epoch \
|
|
--seed 1337
|
|
```
|
|
|
|
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk-10k-steps. The corresponding Weights and Biases report [here](https://wandb.ai/nielsrogge/huggingface/reports/SegFormer-fine-tuning--VmlldzoxODY5NTQ2). Note that it's always advised to check the original paper to know the details regarding training hyperparameters. E.g. from the SegFormer paper:
|
|
|
|
> We trained the models using AdamW optimizer for 160K iterations on ADE20K, Cityscapes, and 80K iterations on COCO-Stuff. (...) We used a batch size of 16 for ADE20K and COCO-Stuff, and a batch size of 8 for Cityscapes. The learning rate was set to an initial value of 0.00006 and then used a “poly” LR schedule with factor 1.0 by default.
|
|
|
|
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
|
|
|
|
## PyTorch version, no Trainer
|
|
|
|
Based on the script [`run_semantic_segmentation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
|
|
|
|
The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
|
|
|
|
First, run:
|
|
|
|
```bash
|
|
accelerate config
|
|
```
|
|
|
|
and reply to the questions asked regarding the environment on which you'd like to train. Then
|
|
|
|
```bash
|
|
accelerate test
|
|
```
|
|
|
|
that will check everything is ready for training. Finally, you can launch training with
|
|
|
|
```bash
|
|
accelerate launch run_semantic_segmentation_no_trainer.py --output_dir segformer-finetuned-sidewalk --with_tracking --push_to_hub
|
|
```
|
|
|
|
and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
|
|
|
|
With the default settings, the script fine-tunes a [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset.
|
|
|
|
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk. Note that the script usually requires quite a few epochs to achieve great results, e.g. the SegFormer authors fine-tuned their model for 160k steps (batches) on [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150).
|
|
|
|
## Reload and perform inference
|
|
|
|
This means that after training, you can easily load your trained model as follows:
|
|
|
|
```python
|
|
from transformers import AutoImageProcessor, AutoModelForSemanticSegmentation
|
|
|
|
model_name = "name_of_repo_on_the_hub_or_path_to_local_folder"
|
|
|
|
image_processor = AutoImageProcessor.from_pretrained(model_name)
|
|
model = AutoModelForSemanticSegmentation.from_pretrained(model_name)
|
|
```
|
|
|
|
and perform inference as follows:
|
|
|
|
```python
|
|
from PIL import Image
|
|
import requests
|
|
import torch
|
|
|
|
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
|
image = Image.open(requests.get(url, stream=True).raw)
|
|
|
|
# prepare image for the model
|
|
inputs = image_processor(images=image, return_tensors="pt")
|
|
|
|
with torch.no_grad():
|
|
outputs = model(**inputs)
|
|
logits = outputs.logits
|
|
|
|
# rescale logits to original image size
|
|
logits = nn.functional.interpolate(outputs.logits.detach().cpu(),
|
|
size=image.size[::-1], # (height, width)
|
|
mode='bilinear',
|
|
align_corners=False)
|
|
|
|
predicted = logits.argmax(1)
|
|
```
|
|
|
|
For visualization of the segmentation maps, we refer to the [example notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SegFormer/Segformer_inference_notebook.ipynb).
|
|
|
|
## Important notes
|
|
|
|
Some datasets, like [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150), contain a "background" label that is not part of the classes. The Scene Parse 150 dataset for instance contains labels between 0 and 150, with 0 being the background class, and 1 to 150 being actual class names (like "tree", "person", etc.). For these kind of datasets, one replaces the background label (0) by 255, which is the `ignore_index` of the PyTorch model's loss function, and reduces all labels by 1. This way, the `labels` are PyTorch tensors containing values between 0 and 149, and 255 for all background/padding.
|
|
|
|
In case you're training on such a dataset, make sure to set the ``do_reduce_labels`` flag, which will take care of this.
|