6.9 KiB
This model was published in HF papers on 2020-10-26 and contributed to Hugging Face Transformers on 2024-01-03.
FastSpeech2Conformer
Overview
The FastSpeech2Conformer model was proposed with the paper Recent Developments On Espnet Toolkit Boosted By Conformer by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
The abstract from the original FastSpeech2 paper is the following:
Non-autoregressive text to speech (TTS) models such as FastSpeech (Ren et al., 2019) can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated and time-consuming, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of fully end-to-end inference. Experimental results show that 1) FastSpeech 2 achieves a 3x training speed-up over FastSpeech, and FastSpeech 2s enjoys even faster inference speed; 2) FastSpeech 2 and 2s outperform FastSpeech in voice quality, and FastSpeech 2 can even surpass autoregressive models. Audio samples are available at https://speechresearch.github.io/fastspeech2/.
This model was contributed by Connor Henderson. The original code can be found here.
🤗 Model Architecture
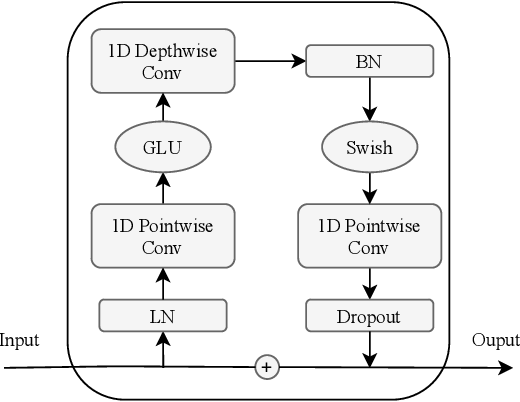
FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
FastSpeech2 Model Architecture

Conformer Blocks

Convolution Module
🤗 Transformers Usage
You can run FastSpeech2Conformer locally with the 🤗 Transformers library.
- First install the 🤗 Transformers library, g2p-en:
pip install --upgrade pip
pip install --upgrade transformers g2p-en
- Run inference via the Transformers modelling code with the model and hifigan separately
import soundfile as sf
from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerModel, FastSpeech2ConformerTokenizer
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt").to(model.device)
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer", device_map="auto")
output_dict = model(input_ids, return_dict=True)
spectrogram = output_dict["spectrogram"]
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram)
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
- Run inference via the Transformers modelling code with the model and hifigan combined
import soundfile as sf
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt").to(model.device)
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"]
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
- Run inference with a pipeline and specify which vocoder to use
import soundfile as sf
from transformers import FastSpeech2ConformerHifiGan, pipeline
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])
FastSpeech2ConformerConfig
autodoc FastSpeech2ConformerConfig
FastSpeech2ConformerHifiGanConfig
autodoc FastSpeech2ConformerHifiGanConfig
FastSpeech2ConformerWithHifiGanConfig
autodoc FastSpeech2ConformerWithHifiGanConfig
FastSpeech2ConformerTokenizer
autodoc FastSpeech2ConformerTokenizer - call - save_vocabulary - decode - batch_decode
FastSpeech2ConformerModel
autodoc FastSpeech2ConformerModel - forward
FastSpeech2ConformerHifiGan
autodoc FastSpeech2ConformerHifiGan - forward
FastSpeech2ConformerWithHifiGan
autodoc FastSpeech2ConformerWithHifiGan - forward