8.2 KiB
This model was published in HF papers on 2022-06-17 and contributed to Hugging Face Transformers on 2023-01-25.
BridgeTower
Overview
The BridgeTower model was proposed in BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
This paper has been accepted to the AAAI'23 conference.
The abstract from the paper is the following:
Vision-Language (VL) models with the TWO-TOWER architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BRIDGETOWER, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the crossmodal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BRIDGETOWER achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BRIDGETOWER achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
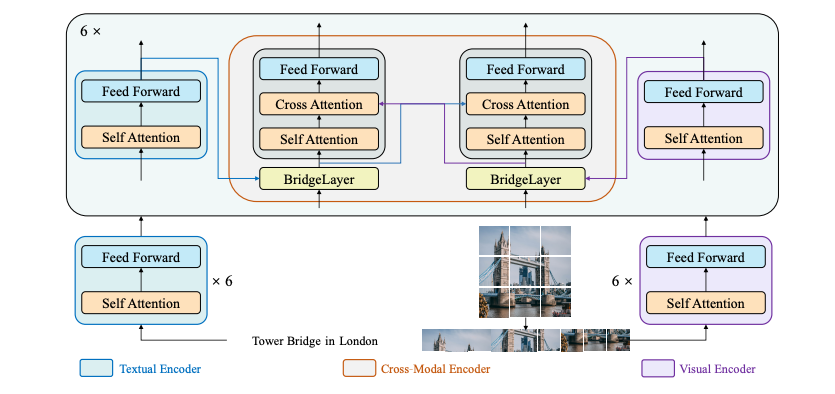
BridgeTower architecture. Taken from the original paper.
This model was contributed by Anahita Bhiwandiwalla, Tiep Le and Shaoyen Tseng. The original code can be found here.
Usage tips and examples
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers. The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder. In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
The [BridgeTowerProcessor] wraps [RobertaTokenizer] and [BridgeTowerImageProcessor] into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using [BridgeTowerProcessor] and [BridgeTowerForContrastiveLearning].
import requests
from PIL import Image
from transformers import BridgeTowerForContrastiveLearning, BridgeTowerProcessor
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc", device_map="auto")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
outputs = model(**encoding)
scores[text] = outputs
The following example shows how to run image-text retrieval using [BridgeTowerProcessor] and [BridgeTowerForImageAndTextRetrieval].
import requests
from PIL import Image
from transformers import BridgeTowerForImageAndTextRetrieval, BridgeTowerProcessor
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm", device_map="auto")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
outputs = model(**encoding)
scores[text] = outputs.logits[0, 1].item()
The following example shows how to run masked language modeling using [BridgeTowerProcessor] and [BridgeTowerForMaskedLM].
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a <mask> looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm", device_map="auto")
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
.a cat looking out of the window.
Tips:
- This implementation of BridgeTower uses [
RobertaTokenizer] to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings. - Checkpoints for pre-trained bridgeTower-base and bridgetower masked language modeling and image text matching are released.
- Please refer to Table 5 for BridgeTower's performance on Image Retrieval and other down stream tasks.
BridgeTowerConfig
autodoc BridgeTowerConfig
BridgeTowerTextConfig
autodoc BridgeTowerTextConfig
BridgeTowerVisionConfig
autodoc BridgeTowerVisionConfig
BridgeTowerImageProcessor
autodoc BridgeTowerImageProcessor - preprocess
BridgeTowerImageProcessorPil
autodoc BridgeTowerImageProcessorPil - preprocess
BridgeTowerProcessor
autodoc BridgeTowerProcessor - call
BridgeTowerModel
autodoc BridgeTowerModel - forward
BridgeTowerForContrastiveLearning
autodoc BridgeTowerForContrastiveLearning - forward
BridgeTowerForMaskedLM
autodoc BridgeTowerForMaskedLM - forward
BridgeTowerForImageAndTextRetrieval
autodoc BridgeTowerForImageAndTextRetrieval - forward